mysql开发技巧
一、mysql开发技巧(join)
(本次操作数据库为 公司8.0开发库 java_test )
sql join的类型
内连接(join)
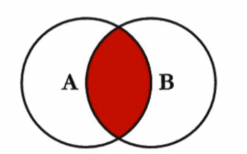
SELECT
u.`user_name`,
u.over,
uf.over
FROM
`user` u
JOIN user_friend uf ON u.`user_name` = uf.`user_name`全外链接(full outer)
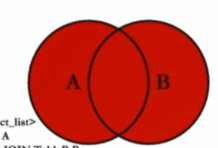
mysql不支持full join 使用左连接 union All 右链接
<-- full join -->
SELECT
u.`user_name`,
u.over,
uf.over
FROM
`user` u
LEFT JOIN user_friend uf ON u.`user_name` = uf.`user_name`
UNION
SELECT
uf.`user_name`,
uf.over,
u.over
FROM
`user` u
RIGHT JOIN user_friend uf ON uf.`user_name` = u.`user_name` 
SELECT
u.`user_name`,
u.over,
uf.over as over1
FROM
`user` u
LEFT JOIN user_friend uf ON u.`user_name` = uf.`user_name`
where uf.over is null
UNION ALL
SELECT
uf.`user_name`,
uf.over,
u.over as over1
FROM
`user` u
RIGHT JOIN user_friend uf ON uf.`user_name` = u.`user_name`
where u.over is null
<-- 或者 -->
select * from
(SELECT
u.`user_name`,
u.over,
uf.over as over1
FROM
`user` u
LEFT JOIN user_friend uf ON u.`user_name` = uf.`user_name`
UNION ALL
SELECT
uf.`user_name`,
uf.over,
u.over as over1
FROM
`user` u
RIGHT JOIN user_friend uf ON uf.`user_name` = u.`user_name` ) t
where over1 is null左外链接(left outer)
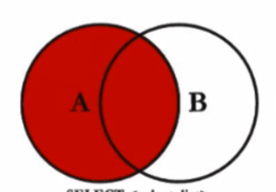
SELECT
*
FROM
`user` u
LEFT JOIN user_friend uf ON u.`user_name` = uf.`user_name`不推荐使用 表B in 表a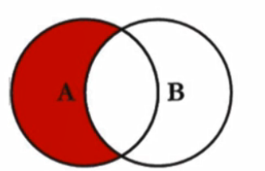
<-- 不是悟空的结拜兄弟 -->
SELECT
*
FROM
`user` u
LEFT JOIN user_friend uf ON u.`user_name` = uf.`user_name`
WHERE
uf.user_name IS NULL右外链接 (right out)
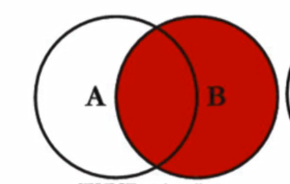
SELECT
*
FROM
`user` u
RIGHT JOIN user_friend uf ON u.`user_name` = uf.`user_name` 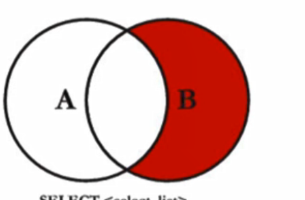
<--悟空的兄弟哪些没有去取经-->
SELECT
*
FROM
`user` u
RIGHT JOIN user_friend uf ON u.`user_name` = uf.`user_name`
WHERE
u.user_name IS NULL交叉链接 (cross)
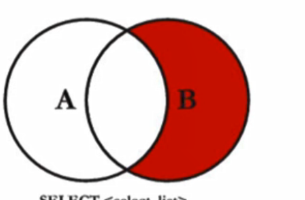
笛卡尔积
SELECT
*
FROM
`user`
CROSS JOIN user_friend使用join更新表
如何更新使用过滤条件中包括自身的表
请假:把同时存在于取经四人组和悟空结拜兄弟中的记录的人在取经四人组表中的over字段更新为“齐天大圣”
<-- 错误示范 不能更新在from从句中出现的表 (mysql不支持)-->
UPDATE `user`
SET over = '齐天大圣'
WHERE
user_name IN ( SELECT u.`user_name` FROM `user` u JOIN user_friend uf ON u.`user_name` = uf.`user_name` )
<--优化2-->
update `user` u
JOIN user_friend uf ON u.`user_name` = uf.`user_name`
set u.over = '齐天大圣'使用join优化子查询
<--子查询-->
SELECT
a.user_name,
a.over,
( SELECT u.over FROM user_friend b WHERE a.user_name = b.user_name ) AS over1
FROM
`user` a;
<-- join优化 -->
SELECT
a.user_name,
a.over,
b.over AS over1
FROM
`user` a
LEFT JOIN user_friend b ON a.user_name = b.user_name;使用join优化子查询聚合子查询
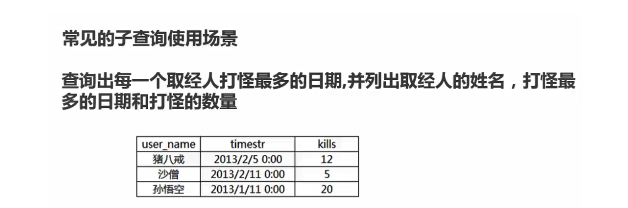
打怪最多的日期
<-- 教程 -->
SELECT
a.user_name,
b.timestr,
b.kills
FROM
`user` a
JOIN user_kills b ON a.id = b.user_id
WHERE
b.kills = ( SELECT MAX( c.kills ) FROM user_kills c WHERE c.user_id = b.user_id )<-- 教材优化 -->
SELECT
a.user_name,
b.timestr,
b.kills
FROM
`user` a
JOIN user_kills b ON a.id = b.user_id
JOIN user_kills c ON c.user_id = b.user_id
GROUP BY a.user_name,b.timestr,b.kills
HAVING b.kills = MAX(c.kills)<-- 自己 (临时表优化子查询) -->
SELECT
a.*
FROM
user_kills a
INNER JOIN ( SELECT user_id, MAX( kills ) AS kills FROM user_kills GROUP BY user_id ) b ON a.user_id = b.user_id
AND a.kills = b.kills如何实现分组数据的选择???
取经四人组每个人杀怪最多的前俩天
<-- 循坏查 不建议 -->
SELECT
a.user_name,
b.timestr,
b.kills
FROM
`user` a
JOIN user_kills b ON a.id = b.user_id
WHERE
a.user_name = "孙悟空"
ORDER BY
kills
LIMIT 2
<-- 优化 -->
SELECT
d.user_name,
timestr,
kills,
cnt
FROM
(
SELECT
user_id,
timestr,
kills,
( SELECT COUNT( * ) FROM user_kills b WHERE b.user_id = a.user_id AND a.kills < b.kills ) AS cnt
FROM
user_kills a
GROUP BY
user_id,
timestr,
kills
) c
JOIN `user` d ON c.user_id = d.id
WHERE
cnt <2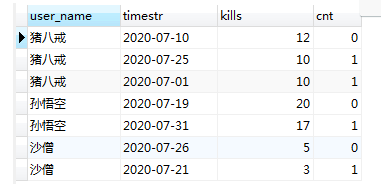
当前俩名有重复数据时会有问题?
SELECT
u.user_name,
a.timestr,
a.kills
FROM
`user` u
INNER JOIN
( SELECT e.*, row_number ( ) OVER ( PARTITION BY user_id ORDER BY kills DESC ) AS row_num FROM user_kills e ) a
on u.id = a.user_id and a.row_num <= 2;1.如何进行行列转换
行转列的场景:
2.1报表统计
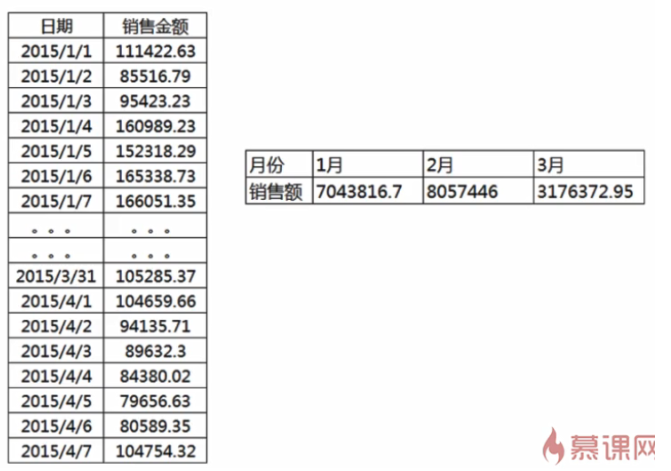
2.2汇总显示
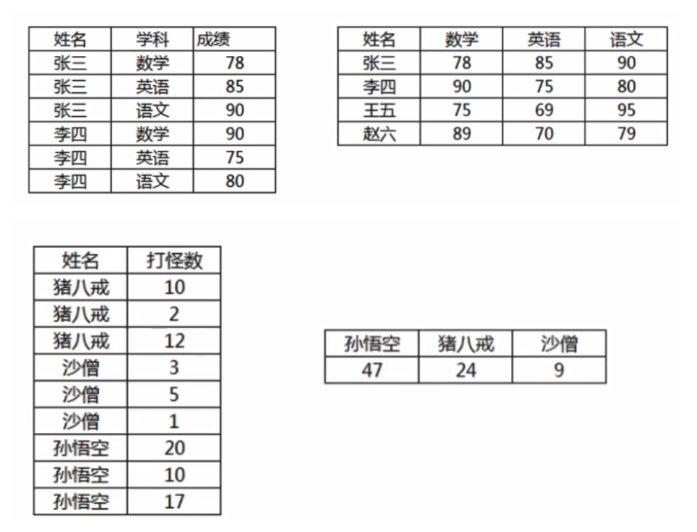
行转列
SELECT
b.user_name,
sum(a.kills)
FROM
user_kills a INNER JOIN `user` b on a.user_id = b.id
GROUP BY
a.user_id<--交叉链接 耗性能 -->
SELECT * FROM
(SELECT sum( a.kills ) AS 沙僧
FROM user_kills a
INNER JOIN `user` b ON a.user_id = b.id
WHERE
b.user_name = "沙僧"
) a
CROSS JOIN (
SELECT sum( a.kills ) AS 猪八戒
FROM user_kills a
INNER JOIN `user` b ON a.user_id = b.id
WHERE
b.user_name = "猪八戒"
) b
CROSS JOIN (
SELECT sum( a.kills ) AS 孙悟空
FROM user_kills a
INNER JOIN `user` b ON a.user_id = b.id
WHERE
b.user_name = "孙悟空"
) c<--优化-->
SELECT
sum( CASE WHEN user_name = '孙悟空' THEN kills END ) AS '孙悟空' ,
sum( CASE WHEN user_name = '猪八戒' THEN kills END ) AS '猪八戒' ,
sum( CASE WHEN user_name = '沙僧' THEN kills END ) AS '沙僧'
FROM
user_kills a
INNER JOIN `user` b ON a.user_id = b.id列转行
SELECT
user_name,
substring_index(substring_index(mobile, ',', a.id),',' ,- 1) AS mobile
FROM
tb_sequence a
CROSS JOIN (
SELECT user_name, mobile,
(length(mobile) - length(REPLACE(mobile, ',', '')) + 1) AS size
FROM
user
) b ON a.id <= b.size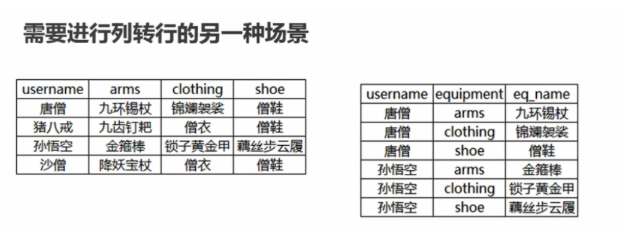
<--耗性能-->
SELECT
user_name,
"arms" AS equipment,
arms
FROM
`user` a
JOIN `user_equipment` b ON a.id = b.user_id UNION ALL
SELECT
user_name,
"clothing" AS equipment,
clothing
FROM
`user` a
JOIN `user_equipment` b ON a.id = b.user_id UNION ALL
SELECT
user_name,
"shoe" AS equipment,
shoe
FROM
`user` a
JOIN `user_equipment` b ON a.id = b.user_id
ORDER BY user_name<--序列化的方式-->
SELECT
user_name,
CASE
WHEN c.id = 1 THEN 'arms'
WHEN c.id = 2 THEN 'clothing'
WHEN c.id = 3 THEN 'shoe'
END AS equipment,
COALESCE (
CASE WHEN c.id = 1 THEN arms END,
CASE WHEN c.id = 2 THEN clothing END,
CASE WHEN c.id = 3 THEN shoe END
) AS eq_name
FROM
user_equipment a
JOIN `user` b ON a.user_id = b.id
CROSS JOIN tb_sequence c
WHERE
c.id <= 3
COALESCE是一个函数, (expression_1, expression_2, ...,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返回一个空值。使用COALESCE在于大部分包含空值的表达式最终将返回空值。2.如何生成唯一序列号


一天之内不能重复

3.如何删除重复数据

<--分组查询重复数据 (group by + having)-->
SELECT user_name, `over`, count(*)
FROM user1
GROUP BY user_name, `over`
HAVING count(*) >1删除重复数据保留id最大的
DELETE a
FROM
user1 a
INNER JOIN (
SELECT
user_name,
count( * ),
MAX( id ) AS id
FROM
user1
GROUP BY
user_name
HAVING
COUNT( * ) > 1
) b ON a.user_name = b.user_name
WHERE a.id < b.id3.1 如何在子查询中匹配俩个值
==子查询:当一个查询是另一个查询的条件时,称之为子查询==
使用场景 :尽量使用连接查询代替子查询 可以避免在子查询表中重复出现的问题
更符合语意,更好了解。
单列:
<-- 子查询 自动去重-->
SELECT
user_name
FROM
`user`
WHERE
id IN ( SELECT user_id FROM user_kills );
<-- 表链接 (一对多或者多对多的关系)DISTINCT去重-->
SELECT
DISTINCT
user_name
FROM
`user` u
JOIN user_kills uk ON u.id = uk.user_id;多列
<--连表的方式-->
SELECT
a.user_name,
b.timestr,
b.kills
FROM
`user` a
INNER JOIN user_kills b ON a.id = b.user_id
INNER JOIN ( SELECT user_id, max( kills ) AS cnt FROM user_kills GROUP BY user_id ) c ON b.user_id = c.user_id
AND b.kills = c.cnt;
==多列join==
<-- 多列子查询-->
SELECT
a.user_name,
b.timestr,
b.kills
FROM
`user` a
JOIN user_kills b ON a.id = b.user_id
WHERE
( b.user_id, b.kills ) IN ( SELECT user_id, max( kills ) FROM user_kills GROUP BY user_id )3.2 解决同属性多值过滤问题
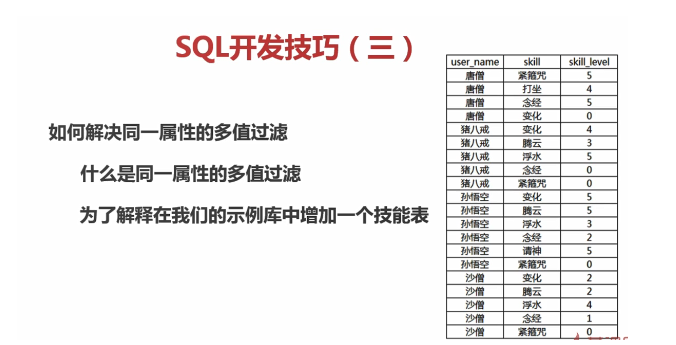
如何查询同时具有变化和念经这俩项技能的取经人???
<--错误写法-->
SELECT
a.user_name,
b.skill,
b.skill_level
FROM
`user` a
JOIN user_skill b ON a.user_name = b.user_name
where skill in ("念经","变化") and skill_level>0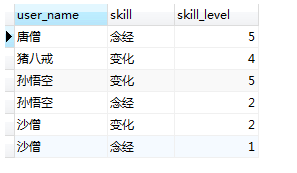
<--优化-->
SELECT
user_name
FROM
(
SELECT
a.user_name,
b.skill,
b.skill_level
FROM
`user` a
JOIN user_skill b ON a.user_name = b.user_name
WHERE
skill IN ( "念经", "变化" )
AND skill_level > 0
) t
GROUP BY
user_name
HAVING
count( user_name ) =2
<--链接查询-->
SELECT
a.user_name,
b.skill,
c.skill
FROM
`user` a
JOIN user_skill b ON a.user_name = b.user_name
JOIN user_skill c ON b.user_name = c.user_name
WHERE
b.skill = '念经'
AND c.skill = '变化'
AND b.skill_level > 0
AND c.skill_level > 0满足几个技能中的任意俩个技能
<--group by-->
SELECT
a.user_name
FROM
`user` a
JOIN user_skill b ON a.user_name = b.user_name
WHERE
skill IN ( "念经", "变化", "腾云", "浮水" )
AND skill_level > 0
GROUP BY
b.user_name
HAVING
count( * ) >23.3 如何计算累进税类问题
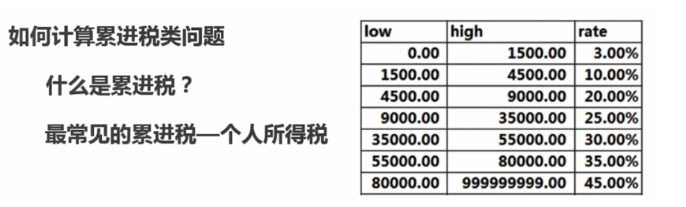
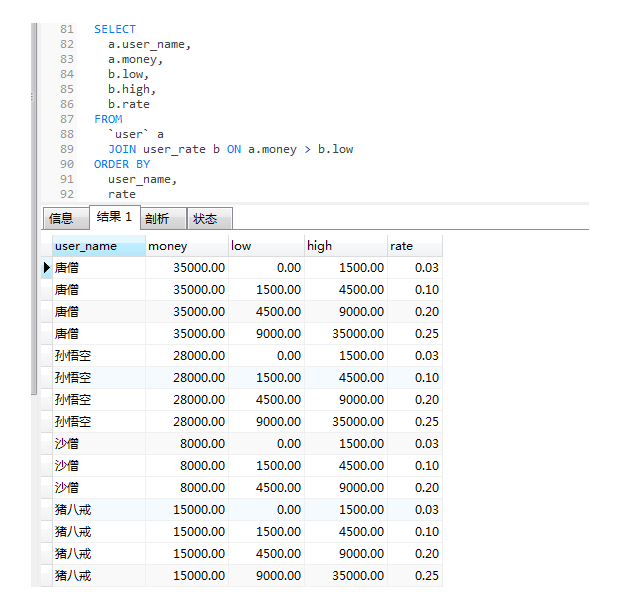
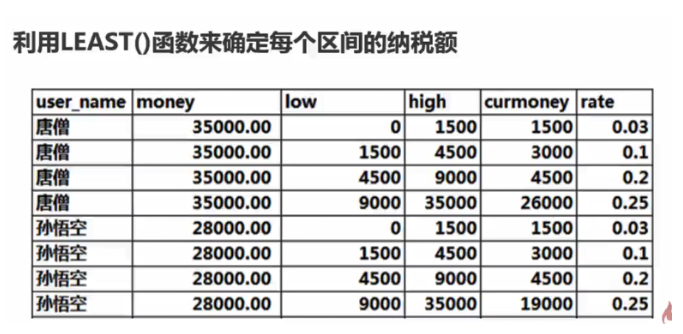
SELECT
user_name,sum( curmoney * rate )
FROM
(SELECT a.user_name,a.money,b.low,b.high,
LEAST( money - low, high - low ) AS curmoney,b.rate
FROM`user` a
JOIN user_rate b ON a.money > b.low
) t
GROUP BY user_name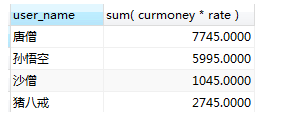
作用适用于搜索
我们要模糊搜索用户表的用户昵称,与最终成就,按照我们以前的写法
select id from `user` where user_name like "%aa%"
UNION
select id from `user` where `over` like "%aa%"<--创建虚拟列-->
alter table `user` add search varchar(50) generated always as(concat(`user_name`,`over`)) ;虚拟列会自动将俩个值拼接起来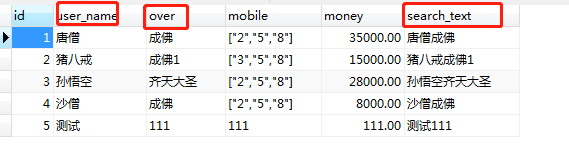
select id from `user` where search_test LIKE "%aa%"
长篇大作啊,牛批~!